Zadání LS 2018/2019
Na tuto stránku vkládejte svá zadání. Nezapomeňte se podepsat. Můžete použít ~~~~ (čtyři tildy) k automatickému podpisu. Používejte Ukázat náhled, abyste si prohlédli Váš výsledek před konečným odesláním. |
Prosíme, snažte se formulovat Vaše zadání pečlive. S ohledem na to, že jde o Vaši semestrální práci, očekáváme adekvátní úsilí vynaložené na zadání. Nezapomeňte, že hlavním výsledkem má být výzkumná zpráva, což znamená, že Váš simulační model musí generovat takové výsledky, které jsou konkrétní, měřitelné a ověřitelné. Pečlivě promyslete, jakým způsobem budete vyvíjet Váš model, odvoďte entity, které budete používat, nakreslete si diagram modelu, zvažte, co budete měřit. Teprve pokud máte o modelu dostatečně přesnou představu, vložte Vaše zadání. A samozřejmě, nezapomeňte si prosím přečíst Jak na simulace. |
Abychom se vyhnuli případnému budoucímu nedorozumnění, prosíme, ověřte si, že máte tučné schváleno někde v našem komentáři pod Vaším zadání. Pokud tam není schváleno, znamená to, že Vaše zadání dosud schváleno nebylo. |
Contents
- 1 Simulace sjezdovky
- 2 Simulace šíření spalniček
- 3 Příjem, zpracování a vyloučení alkoholu z těla
- 4 Simulace optímálneho počtu výčapov piva na štadióne
- 5 Simulace ideálního rozdělení klužiště na rybníkový hokej
- 6 Vytíženost posilovny
- 7 Spotřeba surovin ve fastfoodu
- 8 Simulace automobilových závodů
- 9 Simulace Killer Bees
- 10 Simulace reklamačního oddělení
- 11 Optimalizace centrálního skladu
- 12 Simulace výběru pokladny na prodejně
- 13 Meziměstská autobusová doprava
- 14 Retence vody v krajině
- 15 Simulace populačního vývoje České republiky
- 16 Simulace parkoviště
Simulace sjezdovky
Název simulace: Simulace sjezdovky
Autor: Michal Pokorný
Typ modelu: Multiagentní
Modelovací nástroj: NetLogo
Popis Modelu: Simulace pohybu lyžařů/snowboardistů na svahu. Účastníci simulace jsou nejdříve vyvezeni vlekem/ky na vrcholek svahu a následně v závislosti na svojí strategii sjedou svah dolů. Simulace by řešila optimální počet a průchodnost vleků v závislosti na počtu účastníků (toto lze řešit výpočtem), počet nehod v závislosti na počtu vleků/účastníků a porovnání jednotlivých strategií účastníků (jejich rychlost) s pravděpodobností jejich srážky s jiným účastníkem.
Parametry modelu:
- Velikost svahu
- Počet účastníků
- Strategie (rychlost) účastníků
- Počet a rychlost vleků
Možné rozšíření: Úprk před lavinou, různé typy (rychlosti) sjezdovek, možnost pádu účastníka bez srážky s jiným účastníkem, různé obtížnosti sjezdovek (vyšší četnost pádů), vliv strategie na četnost pádů
- Nevidím tady mnoho důvodů k agentní simulaci. Vychází mi z toho simulace diskrétní a to ještě poměrně jednoduchá. Popřemýšlel bych buďto, jak to transformovat do simulace vhodné pro agenty (viz kritéria diskutovaný na poslední hodině) nebo to dělat jako diskrétní simulaci (ale v tom případě by bylo dobré trochu zvýšit složitost) či popřemýšlet o něčem úplně jiném. Tomáš (talk) 19:27, 5 May 2019 (CET)
- Doplňuji s odstupem pár dnů - vemte si prosím případ nějaké konkrétní sjezdovky (velká lyžařská centra mají poměrně detailní mapy a dokonce jsou k dispozici i nějaké informace o kapacitách a vytížení) a pak by to smysl jako agentní simulace dávalo. Pokud je to v takovéhle modifikaci za Vás OK, pak schváleno. Tomáš (talk) 18:43, 8 May 2019 (CET)
Simulace šíření spalniček
Název simulace: Simulace šíření spalniček
Autor: Bc. Jurij Povoroznyk, povj01
Typ modelu: Systémová dynamika
Modelovací nástroj: Vensim
Popis Modelu: V České republice propukla epidemie spalniček. Tato nemoc se k nám dostal od cestovatele z Indie přímo do hlavního města Prahy. Celkově bylo nakaženo 2 000 lidí a další lidé rychle přibývají. Nakažený jedinci jsou z různých věkových kategorií. Přičemž děti v rozmezí 3–5 let jsou na tuto nemoc náchylnější a můžou této nemoci rychle podlehnout, dokonce umřít pokud nejsou již očkování. Očkovat dítě je možné minimálně od 1 roku života. Bylo zjištěno, že z celého souboru nebylo očkováno ani jednou dávkou vakcíny 39 % osob. Dvěma dávkami vakcíny bylo očkováno 42 % nakažených. Onemocnění se projevuje horečkou, rýmou, kašlem, slzícíma očima a na bukální sliznici jsou bělavé tečky se zarudlým okolím. Virus spalniček se přenáší kapénkovou infekcí. Inkubační doba spalniček je 6–19 dní, průměrně 13 dní. Infikovaní lidé jsou nakažliví ještě 4 až 5 dní před propuknutím této nemoci. Úmrtnost je velmi malá, 3 smrti z 1 000 případů. U dětí, které nedostali vakcínu a jsou nakažený touto chorobou je patřičně větší.
Parametry modelu:
- Počet infikovaných
- Počet zdravých
- Počet jedinců z různých věkových kategorií
- Očkovaných jednou vakcínou, dvěma nebo žádnou
- Počet mrtvých
- Těžce nemocný jedinci
Cíl simulace: Cílem tohoto modelu je určit a sledovat průběh této epidemie. Zároveň pomocí tohoto modelu lze určit, jak budou na tuto epidemii reagovat různé věkové kategorie a počet vakcín obdržených před vypuknutím epidemie. Údaje získané z této simulace by měly přesvědčit rodiče k očkování svých děti ihned jak to bude možné.
Možnosti rozšíření: Model lze rozšířit o konkrétnější data - např.: typ vakcíny, absolvovaná karanténa nebo počet zdravých jedinců v rodině. Celkově se model rozšíří pokud budou adekvátní přibližná data a statistiky propuklé epidemie.
- Není mi úplně jasné, jak by to mělo vypadat a proč to chcete dělat jako agentní simulaci. Vezměte si prosím ta kritéria, která jsme si říkali na poslední hodině a otestujte si, kterým to vyhovuje. Tak jak je to popsáno by to podle mě spíš směřovalo do systémové dynamiky. Zkuste to prosím buď jinak navrhnout nebo zvolit jiný nástroj nebo eventuálně jiné téma. Tomáš (talk) 19:45, 5 May 2019 (CET)
- Děkuji za Váš komentář. Hlavním důvodem výběru multiagentní simulace a konkrétně nástroje NetLogo je využití více typů jednotlivých agentů s rozlišnýma vlastnostmi a různorodýma reakcemi mezi sebou. Půjde především o lidi, kteří se budou lišit jak věkovou kategorií, tak samotnou šancí získat tuto nemoc dle výše zmíněných statistik získaných z ČSÚ. Dalším agentem je samotný virus. Mimo to by bylo možné přidat karanténu, kdy lidi budou uzamčený a nebudou moci nakazit ostatní zdravé jedince. Ovšem nedokážu si představit, jak to bude náročné na samotné programování. Zároveň vypuklá epidemie spalniček bude mít větší šanci nakazit jedince se slabší imunitou. Z výše uvedených informací mi přijde, že multiagentní simulace je nejvhodnější variantou pro aplikování této simulace. Povj01 (talk) 11:39, 10 May 2019 (CET)
- To co píšete, samozřejmě smysl dává. Nicméně, obecně se šíření chorob často zvrhne v jakési hemžení, kde si nakažení vzájemně předávají infekci. Nakolik to pak má kontakt s realitou, je často dost diskutabilní, proto se ptám předem, jak by to mělo vypadat a je opravdu důležité, abyste to měl rozmyšleno. Klidně sem prosím připojte nějaký nákres. Tomáš (talk) 16:48, 12 May 2019 (CET)
- Děkuji za odpověď. V příloze zasílám vytvořený návrh. Jde především o představu vytvořenou ve Photoshopu, tudíž se může částečně lišit od finální verze simulace. S realitou to bude mít velkou spojitost. Ať už jde o samotná čísla, která budou reálná a budou získaná z ČSÚ nebo vytvoření 1 či více karantén, jenž se vytvoří po velkém seskupení nemocných na jednom místě. Toto řešení by mohlo obohatit výsledek, zda vytvoření této karantény zabrání šíření a zda je vhodné vytvořit jednu či více. U jednotlivých agentů vytvořených v návrhu půjde také o dávky které získali jako prevenci proti spalničkám. U těchto simulací si nedokážu, jak více to lze propojit s realitou. Napadá mě ještě udělat nějakou reálnou budovu, např.: VŠE, kde se tyto spalničky budou šířit. Toto téma jsem si především vybral právě po reálném objevení spalniček na půdě VŠE. Odkaz na představu simulace se nachází zde! Povj01 (talk) 19:07, 12 May 2019 (CET)
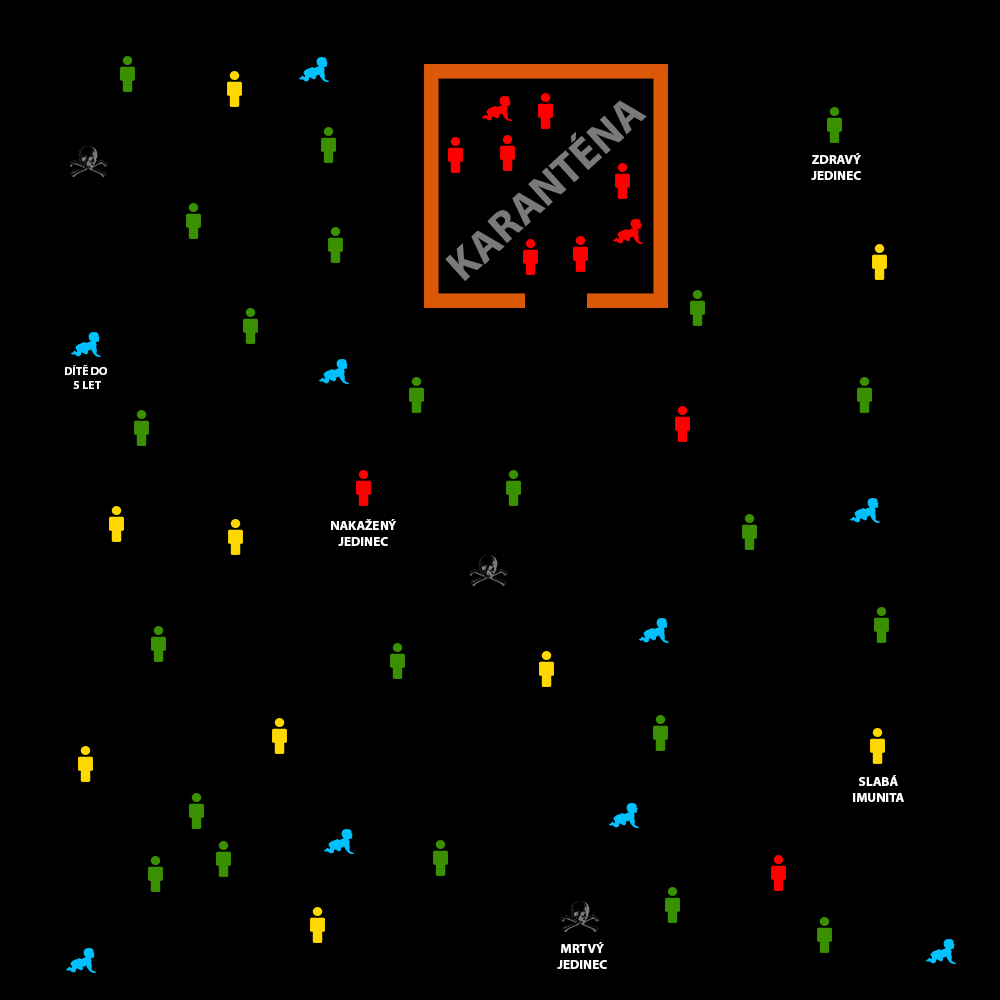{kind=link}
- Tohle je to, čemu říkám "hemžení". Ve skutečnosti budete mít problém, aby vám v takovém modelu fungovala statistika. Na to totiž potřebujete mít pro každý dílčí jev dostatečné množství výskytů. To se dá ještě jakžtakž zajistit co se týče nějakého šíření epidemie, ale už musíte zanedbat prostorové aspekty, protože na takto malé ploše s takto málo agenty by došlo k obrovskému zkreslení výsledků (bavíme se o dejme tomu desítkách výskytů v desetimilionové populaci, o je z hlediska simulace strašlivě málo). Z toho vyplývá i problém s karanténou. Kolik lidí se do ní dostane? Rozumím tomu dobře, že jsou to ti, co "vlezou do té místnosti"? V tom případě je příslušnou proměnnou šířka toho vstupu. Atd. To téma je zajímavé a jsem pro, ale obávám se, že agentní simulace je pro něj nevhodná (alespoň pokud je formulováno tak, jak je formulováno). Simulace epidemií běžně pracují s miliony agenty, což v NetLogu moc dobře nejde. Jinak vám bude vycházet, že prakticky nikdo neonemocní nebo všichni rychle pomřou. Zvážil bych systémovou dynamiku. Tomáš (talk) 19:20, 12 May 2019 (CET)
- Systémová dynamika je na to vhodná, takže ano.Schváleno. Pozor na to, jak to pak pojmete, aby simulace byla přiměřeným způsobem komplexní. Oleg.Svatos (talk) 19:55, 12 May 2019 (CET)
Příjem, zpracování a vyloučení alkoholu z těla
Název simulace: Příjem, zpracování a vyloučení alkoholu z těla
Autor: Bc. Josef Čekan, cekj01
Typ modelu: Systémově dynamický
Modelovací nástroj: Vensim
Popis Modelu: Tento model ukazuje účinek alkoholu na lidské tělo, když sleduje jeho příjem, zpracování a vylučování z těla. Model na základě několika faktorů dokáže odhadnout množství alkoholu v krvi po celou dobu užívání i odbourávání alkoholu, stejně jako dobu potřebnou k jeho úplnému odbourání. Hlavními faktory v modelu jsou váha jedince, typ alkoholu, množství konzumovaného alkoholu a doba samotné konzumace. Na model a jeho výsledky poté mají vliv například počet skleniček za hodinu, míra obsaženého alkoholu, objem tekutin v těle, Michaelisova konstanta či míra tolerance k alkoholu.
Parametry modelu:
- Váha jedince
- Délka trvání konzumace alkoholu (včetně hodinové frekvence)
- Množství konzumovaného alkoholu
- Typ alkoholu
Cíl simulace: Na základě získaných dat dokáže model vykreslit graf s množstvím promile v každém čase od začátku užívání alkoholu až do konce jeho odbourávání. Pomocí tohoto modelu tak lze například zjistit způsobilost(vzhledem k povolené míře alkoholu v krvi v závislosti na státě) k řížení vozidla pro konkrétního člověka dle množství a typu alkoholu. Stejně tak je pomocí modelu možné zjistit za jak dlouho bude veškerý alkohol z těla odbourán.
Možnosti rozšíření:
- Schváleno, ale zamyslte se nad tím, jak ten model udělat komplexnější, aby z toho nevylezla jen jednoduchá kalkulace. Oleg.Svatos (talk) 12:40, 12 May 2019 (CET)
- Změna tématu. Omlouvám se, ale ačkoliv mi výše uvedené téma bylo schváleno, po veškeré snaze nebylo dosaženo dostatečné komplexnosti modelu v takové úrovni, aby se jej dalo považovat za simulaci a nikoliv za pouhý výpočet na základě několika zadaných proměnných. Tímto bych rád požádal o změnu tématu a to konkrétně na téma simulace IT firmy vzhledem k množství zákazníků a zaměstnanců. Jedná se o fiktivní(nekonkrétní) společnost, která nabízí IT služby svým zákazníkům. Jejími zákazníky jsou jiné společnosti. Míněná IT společnost se dostala do kritického stavu, kdy předešlé úspěchy firmy vystřídaly potíže s problémy na straně zákazníků spojené s kvalitou poskytovaných služeb. Kvalita poskytovaných služeb se odvíjí od tlaku na zaměstnance, jenž je zase ovlivňován vytížeností zaměstnanců. Témá bude zpracováno pomocí aplikace Vensim. Jedná se o systémově dynamickou úlohu. Téma bylo zvoleno především pro naplnění požadavků pro semestrální práci a její využití spatřuji především v konfiguraci pro kteroukoliv konkrétní firmu a možností upravení jejích vnitřních nastavení pro dosažení lepšího požadovaného výstupu.
Simulace optímálneho počtu výčapov piva na štadióne
Název simulace: Simulace optímálneho počtu výčapov piva na štadióne
Autor: Bc. Dominik Turák, turd01
Typ modelu: Diskrétni simulace
Modelovací nástroj: Simprocess
Popis Modelu: Na hokejových alebo futbalových zápasoch sa často stáva, že človek musí čakať na pivo v dlhom rade celú večnosť. Navyše, ak sa poblízku štadióna nachádza podnik, v ktorom tiež čapujú pivo, ľudia sa mnohokrát rozhodnú ísť si radšej načapovať pivo tam, pretože je to pre nich mnohokrát výhodnejšie, či už z časového alebo finančného hľadiska. Štadión tým pádom stráca potencionálny zisk a naopak, pri malom počte ľudí zbytočne prepláca pracujúcich výčapníkov.
Model bude obsahovať tieto data:
- X fanúšikov na štadióne, ktorí chcú pivo
- Y výčapov na štadióne
- Z výčapov mimo štadióna
- cena piva na štadióne
- cena piva v konkurenčných výčapoch
Cíl simulace: Nájsť otpimálny počet výčapov prihľiadnúc na počet ľudí na štadióne tak, aby sa minimalizovali straty od nedočkavých ľudí, ktorí si radšej zvolia konkurenčný výčap
Možnosti rozšíření: Rozdielne ceny piva v konkurenčných výčapoch, počet konkurenčných výčapov a vzdialenosti výčapov od štadióna
- Nevidím v tomto zadání nějakou přidanou hodnotu. Co by mělo být přínosem? Velmi rychle byste zjistil, že výsledek je předvídatelný a závislý především na modelu chování účastníků. Doporučoval bych to přehodnotit. Tomáš (talk) 20:56, 5 May 2019 (CET)
- Tak som nad tým premýšľal a rád by som asi spravil niečo úplne iné. Rád by som urobil simulaci optimálneho počtu výčapov na štadióne : X ludi, Y výčapov na štadióne a Z konkurenčných výčapov mimo štadiónu. Prínosom tejto simulácie by mala byť optimalizácia počtu výčapov na štadióne podľa počtu divákov na štadióne a minimalizácia strát sposobená dlhým čakaním na pivo a voľbou ísť si načapovať pivo do konkurenčnej krčmy blízko štadiónu.Dominik (talk) 18:10, 12 May 2019 (CET)
Simulace ideálního rozdělení klužiště na rybníkový hokej
Název simulace: Simulace ideálního rozdělení klužiště na rybníkový hokej
Autor: David Lisý, xlisd05
Typ modelu: diskrétní simulace
Modelovací nástroj: SIMPROCESS
Popis Modelu: Jelikož hokej závodně hraji, rozhodl jsem se na toto téma zpracovat i svou simulaci. V současnosti je trendem pro závodní, ale především pro rekreační hráče tzv."rybníkový hokej". Ten se hraje bez výstroje, v počtu 4 na 4, na malé branky a na třetinu jednoho klasického kluziště (na jedné klasické ledové ploše tedy máme 3 hrací plochy pro rybníkový hokej). Z vlastní zkušenosti mohu potvrdit, že hrají-li spolu pohromadě závodní hráči s hráči amatérskými, výsledná hra ztrácí na své kvalitě. Je proto lepší, hrají-li zápas proti sobě hráči stejné výkonnostní kategorie. Rozlišujeme pak tyto:
- závodní hráč (hráč se zkušenostmi z profesionálních, či závodních soutěží) - pokročilý amatérský hráč (hráč se zkušeností z rekreačních soutěží) - amatérský hráč - začátečník (hráč bez jakýchkoliv zkušeností z rekreačních soutěží)
Data budou čerpána z reálného zimního stadionu v Praze, který disponuje 2 ledovými plochami (celkově tedy simulace sleduje 6 hracích ploch pro rybníkový hokej). Podstatný fakt je ten, že se tedy hraje 4 na 4, střídá se stylem "poslední do hry - poslední na střídačku" (na střídačce se nám tedy tvoří jakási fronta hráčů) a počet hráčů na jedné střídačce není nikterak omezen. Na základě vlastního pozorování budu v simulaci počítat s následujícím procentuálním rozdělením výkonnostních kategorií:
- závodní hráči = 15% - pokročilí amatérští hráči = 60% - amatérští hráči - začátečníci = 25%
Parametry modelu:
- počet hráčů
- průměrná doba hraní na stadionu
- počet hracích ploch pro rybníkový hokej (6)
Cíl simulace: pomocí simulace zjistit ideální rozvrhnutí hracích ploch dle výkonnostních kategorií
Schváleno Tomáš (talk) 18:45, 8 May 2019 (CET)
Vytíženost posilovny
Název: Vytíženost posilovny
Autor: Martin Matějka, xmatm82
Nástroj: SIMPROCESS
Definice problému:
V dnešní době je velice populární zajít si zacvičit nebo se jen tak protáhnout do pohodlné, hezky vybavené posilovny. Jelikož je tento způsob cvičení v dnešní době tak populární, je dobré vědět, jak si na tom určitá posilovna stojí z hlediska schopnosti pokrytí návševnosti. Jak z pohledu zákazníka, tak i provozního, co by mohl zlepšit.
Mají dostatek místa? Dostatek nástrojů či pomůcek na posílování? Mají všichni možnost se dojít osprchovat bez delšího čekání nebo nevázne to hnedka u vchodu při koupi vstupenky?
Metoda: V simulaci bude zahrnuta spousta entit, které budou mít na výsledné hodnoty vliv (druh zákazníka, doba návštěvy..), ale jednou z nejdůležitějčích entit je množství a frekvence návševníků přicházející do posilovny. Pro generování návštěvníků bude použit určitý algoritmus, který bude produkovat náhodná čísla, ale také bude zahrnovat učité hodnoty ze známého chování návštěvníků. Například, že v dopoledních hodinách je nevštěvnost o něco měnší a nebo o víkendech zase vyšší. Pro zanalyzování vytíženosti posilovny v čase je Monte Carlo dobrá volba.
- Zdravím, co všechno by byly tedy náhodné proměnné? Na základě jakých reálných dat budete odvozovat jejich pravděpodobnostní rozdělení? (data a odvození pravděpodobnostních rozdělení musí být součástí vypracované simulace). Jak přesně bude simulace fungovat? Předpokládám, že i když zmiňujete Monte Carlo, tak jako nástroj jste si vybral Simprocess, což je v tomto případě relevatní - v Excelu by udělat nešlo. Oleg.Svatos (talk) 12:11, 4 May 2019 (CET)
- Odpověďi:
- 1)Náhodné proměné?
- počet návštěvníků
- zaměření návštěvníka
- fitness partie (horní, dolní, full-body)
- cardio
- volba nástrojů na cvičení
- popřípadě i doba návštěvy
- 2)Reálných dat? Co se týče vybavení posilovny (druhy,počty strojů), mohu sestavit několik šablon, které v reálu představujou posilovny, které znám. Návštěvnost bude taková, aby byla reálná a také trochu hraniční, aby byla známa přibližná maximální zatíženost posilovny. Dále čas strávených na určitých posilovacích zařízení budou stanoveny podle mého vlasního uvážení, které vychází z mnoha let zkušeností.
- 3)Jak bude fungovat? Budou přícházet návštěvnící do posilovny. Která má stanovený počty několika druhů vybavení. Každý návštěvník má určité zaměření, co chce posilovat a tím je stanoveno jaké stroje by chtěl použít. Použije pár strojů, vysprchuje, oblíkne a odejde. Budem sledovat jaké stroje jsou nejvíce/nejméně vytíženy. Kde má posilovna nedostatny atd. Xmatm82 (talk) 19:34, 7 May 2019 (CET)
- V pořádku, nicméně: opatřete si data z nějaké konkrétní posilovny/posiloven. Z kontextu jsem pochopil, že Vám toto prostředí není cizí, neměl by to pro Vás být tedy problém. Vlastní zkušenost je důležitá, ale někdy nekoresponduje zcela s realitou. Dále, tak jak to popisujete (náhodné volby různých posilovacích strojů apod.), není úplně triviální. Lze to udělat, každopádně potřebujete ostrou verzi Simprocessu (je na učebnách). Schváleno. Tomáš (talk) 18:51, 8 May 2019 (CET)
Spotřeba surovin ve fastfoodu
Název: Spotřeba surovin ve fastfoodu
Autor: Josef Kočí
Nástroj: Simprocess
Definice modelu: Protože již 4 roky pracuji ve společnosti AmRest, z pozice hlavního instruktora mám přístup k manažerským systémům, kde lze sledovat data o prodeji, počtu objednávek v různých hodinách a spotřebu jednotlivých ingrediencí. Mým cílem je část této reality zachytit v programu Simprocess, zobrazit v něm proces na jednotlivých ingrediencích, jejich objednání a naskladnění ráno, jejich průběžné vyskladňování, použití do procesu až k vydání zákazníkům. Proces tak zachytí, kolik dle simulací průměrně zůstává nevyužitých ingrediencí, jak dlouho přibližně zákazníci čekají a pokusím se případně i o analýzu zlepšení tzv. SOS (Speed of Service).
Data: Vstupní data jako množství zákazníků v jedno hodinách či spotřeba ingrediencí sice budou náhodná (avšak vzájemně spolupracující), nicméně budu vycházet z reálných dat z manažerských systémů tak, aby počty objednávek na různé hodiny přibližně seděly.
Doplnění: Prostředí bude přímo z KFC, jelikož ale Simprocess má limitované množství entit, nezachytím bohužel všechny suroviny, které se v KFC používají. Proto se pokusím zachytit ty nejdůležitější. Mezi hlavní cíl patří monitoring zbylých surovin a pokusit se o minimalizaci jejich množství, které na konci zbyde. Budu tedy hledat kritická místa, o nichž pak sepíšu zprávu. Mým cílem tedy bude dosáhnutí co nejmenšího zbytku surovin na konci dne. Z vlastní zkušenosti vím, že není možné skončit s naprosto prázdným stavem, neboť to ve výsledku může negativně ovlivnit SOS v průběhu posledních hodin. V modelu se pochopitelně pokusím o co nejvěrnější proces, tedy sendviče se nějakou dobu zpracovávají, maso se nějakou dobu připravuje a pak nějakou dobu smaží. Uvidím, jak detailně se mi proces povede zachytit.
- Téma je OK, ale je potřeba jej zpřesnit. 1) Stanovte zcela konkrétní cíl(e). Z toho zadání mi to moc konkrétní nepřijde. Co je cílem? Minimalizace zásob? Je to issue? 2) Amrest má pokud vím více brandů. Uvidíte podle definice cíle, ale pravděpodobně bude dobré vyberte si jeden a nasimulovat jej do detailu. 3) Je potřeba zohlednit všechny faktory, které mohou být s ohledem na výsledek relevantní. Předběžně to má zelenou, ale rozpracujte to zadání prosím dopodrobna. Tomáš (talk) 21:06, 5 May 2019 (CET)
- Vaší úpravy jsem si všiml až teď - je lepší změnu nějak označit. Simprocess nemá omezené množství entit, pouze ta zkušební verze to tak má, ale říkali jsme si, že seminárku budete dělat ve verzi ostré, která je nainstalována na učebnách, čili důvod k jakýmkoliv omezením není. Za těchto podmínek schváleno. Tomáš (talk) 19:30, 12 May 2019 (CET)
Simulace automobilových závodů
Název: Simulace automobilových závodů
Autor: Jinv00 (talk) 10:51, 5 May 2019 (CET)
Nástroj: Netlogo
Typ modelu: Multiagentní
Popis modelu: Simulace pohybu závodních vozů po okruhu. Vozy jsou na začátku závodu seřazeny na startovní rovince, a po odstartování krouží po okruhu. Každý vůz může mít různou (náhodně přidělenou) rychlost. Rychlost vozů je kromě základní přidělené rychlosti závislá i na míře opotřebení pneumatik (opotřebovanější pneumatiky jsou pomalejší než méně opotřebované), na aktuální zvolené směsi pneumatik (měkčí směs pneumatik je rychlejší než tvrdší) a na jízdním stylu řidiče (agresivní jízdní styl je rychlejší než konzervativní). Rychlost opotřebovávání pneumatik je závislá na zvolené směsi pneumatik (měkčí směs pneumatik se opotřebovává rychleji než tvrdší), na jízdním stylu řidiče (agresivním jízdním stylem se pneumatiky opotřebovávají rychleji než konzervativním jízdním stylem) a na vzdálenosti vozu za jiným vozem (jízda do cca 2 sekund za jiným vozem má za následek ztrátu přítlaku, pronásledující vůz tak po trati více "klouže" a tím trpí pneumatiky). Přezouvání pneumatik se provádí během pit stopů, které trvají nějaký čas (a k tomu samotná jízda boxovou uličkou je pomalejší než jízda po okruhu). Projede-li vůz za jiným detekční zónou pro DRS s odstupem menším než 1 sekundu, můžu potom v následující DRS zóně využít DRS pro krátkodobé zvýšení rychlosti. Každý vůz musí během závodu použít alespoň 2 různé směsi pneumatik.
Parametry modelu:
- Počet vozů
- Počet kol závodu
- Rychlost vozů (náhodná v intervalu od nejnižší zadané rychlosti po nejvyšší zadanou)
- Průměrná míra opotřebení jednotlivých směsí pneumatik
- Míra vlivu opotřebení pneumatik na rychlost vozu
- Míra vlivu použité směsi pneumatik na rychlost vozu
- Míra vlivu jízdního stylu řidiče na rychlost vozu
- Rychlost opotřebovávání jednotlivých směsí pneumatik
- Míra vlivu jízdního stylu řidiče na míru opotřebení pneumatik
- Míra vlivu jízdy v závěsu (do cca 2 s) za jiným vozem na opotřebení pneumatik
- Rychlost vozů v boxové uličce
- Rychlost vozů v DRS zóně
- Zvolená směs pneumatik jednotlivých vozů na startu závodu
- Počet zastávek v boxech
Cíl simulace: Simulací by se dala odhadnout optimální strategie zastávek v boxech (počet zastávek, načasování zastávek, použité sady pneumatik (a jejich počet)) a optimální jízdní styl (agresivní/konzervativní).
Možnosti rozšíření: Pravděpodobnosti předjetí v různých částech tratě (v mnou navrženém modelu rychlejší vůz vždy kdekoliv předjede pomalejší, ve skutečnosti je však předjetí nejpravděpodobnější na dlouhých rovinkách (ideálně za asistence DRS) a v zatáčkách s větší šířkou tratě; v modelu vůbec neuvažuji zdržení jednoho vozu za druhým kvůli nemožnosti ho předjet). Kolize (v mnou navrženém modelu sebou mohou jednotlivé vozy "projet" bez jakékoliv možnosti havárie). Slipstream - vůz jedoucí za jiným (především při vyšších rychlostech) může využít slipstream vznikající za pronásledovaným vozem ke zvýšení rychlosti. Různá rychlost vozů v různých částech tratě - vyšší rychlost na rovinkách, nižší v zatáčkách (v mnou navrženém modelu je rychlost vozu na celé trati vždy stejná (kromě boxové uličky a DRS zón)), k tomu by šlo přidat i různé nastavení vozů (vyšší přítlak = vyšší rychlost v zatáčkách a menší na rovinkách, nižší přítlak = nižší rychlost v zatáčkách a vyšší na rovinkách). Simulace množství paliva ve vozech (vliv jízdního stylu řidiče na spalování paliva (agresivní = rychlejší spalování paliva, konzervativní = pomalejší spalování), vliv množství paliva ve vozech na rychlost vozu (více paliva (těžší vůz) = pomalejší, méně paliva (lehčí vůz) = rychlejší) a simulace možnosti přidání tankování paliva během zastávek v boxech. Různé opotřebení jednotlivých pneumatik na voze závislé na různých nastaveních vozu (v mnou navrženém modelu se všechny pneumatiky opotřebovávají stejně a stejnou mírou, ve skutečnosti je však opotřebení pneumatik závislé na orientaci okruhu (pravotočivý/levotočivý) a na různých nastaveních vozu (přítlak předního/zadního přítlačného křídla, geometrie zavěšení, odemknutý/zamknutý diferenciál, brake bias (vyvážení brzd (přední vs zadní kola)), tlak v pneumatikách, tlak brzd, rozmístění hmotnosti (či umístění balastu), atd.)).
- To řešení kolizí by mi v tom modelu připadalo jako poměrně podstatné. Jinak to ale vypadá dobře. Schváleno. Tomáš (talk) 21:54, 5 May 2019 (CET)
Simulace Killer Bees
Název simulace: Simulace střetu populací Evropských a Afrikanizovaných včel medonosných
Autor: Michaela Trnková
Typ modelu: Multiagentní
Modelovací nástroj: NetLogo
Popis modelu: V padesátých letech minulého století stvořil vědec v Brazílii křížence africké a evropské včely medonosné. Afrikanizované včely sice produkují až dvojnásobné množství medu než původní evropský druh, zato si ale zachovaly svoji hyperagresivitu danou množstvím predátorů v Africe. Oproti tomu evropské včely byly po staletí šlechtěny k mírnému chování. V roce 1957 uniklo 26 rojů z původního chovu a dnes tvoří dominantní druh od Jižní Ameriky až po jižní státy USA. Uvádí se, že území, kde dominují afrikanizované nebo hybridní druhy, se každý den posune o dva kilometry na sever.
V modelu se budou populace včel potkávat a křížit mezi sebou. Při vzniku hybridu bude mít hybrid šanci získat buď mírné, nebo hyperagresivní chování.
Existují dva druhy včelích hnízd: člověkem udržované úly a hnízda v přírodě. U lidí mají větší šanci na přežití včelstva s mírnou povahou. Ve volné přírodě naopak včelstva agresivní. Afrikanizované včely mohou také obsadit úl včel evropských nahrazením původní královny.
Prostředí budou tvořit různé "klimatické" zóny s jinými teplotními podmínkami. Čím teplejší a vlhčí zóna, tím více medu dokáží vyprodukovat afrikanizované včely. Naopak čím chladnější nebo sušší zóna, tím menší šanci mají afrikanizované včely šanci přežít. Konflikt těchto dvou druhů a jejich hybridů je častým předmětem zkoumání a měla by být dostupná data pro celkem přesný model.
Cílem modelu bude sledovat, jak se bude situace vyvíjet v čase a jaká kritéria jsou rozhodující pro prosperitu jednotlivých druhů.
Parametry modelu:
- Počet možných úlů na území
- Druh zóny a její klima
- Strategie včelařù (preference zisku medu, mírnějšího včelstva aj.)
- Šance na zánik úlu
- Šance na vytvoření nového roje
- Pravděpodobnost zdědění jednotlivých vlastností
Možnosti rozšíření:
- Nemoci včelstev (některé včely jsou odolnější/náchylnější)
- Výkyvy počasí (mimořádně chladná zima/horké léto/sucho,...)
Xtrnm15 (talk) 09:46, 13 May 2019 (CET)
Jo, to je dobré. Schváleno. Tomáš (talk) 11:08, 15 May 2019 (CET)
Simulace reklamačního oddělení
Název: Simulace reklamačního oddělení
Autor: Pavel Gregor
Nástroj: Simprocess
Předmět simulace: Firma poskytuje zákazníkovi službu a to takovou, že pokud se zákazníkovi zakoupené zboží jakkoli rozbije i vlastním zaviněním, dostane výměnou nový kus za stávající. Vrácené jednotky pak procházejí testovacím procesem funkčnosti. Rozbité jednotky jsou přeposílány na rozebrání. Rozebrané jednotky se pak využijí na náhradní díly. Otestované jednotky, které projdou celým procesem, bez nalezené chyby jsou vráceny zpět do oběhu za sníženou cenu.
Na každé pozici má operátor předepsaný počet jednotek, které musí v daném čase otestovat. V simulaci bude řešen počet jednotlivých operátorů na daných pozicích, aby nedocházelo k hromadění jednotek na některých z pozic, které jsou časově náročnější. Dále kolik je zapotřebí operátorů v závislosti na počtu přijatých jednotek. Upravení počtu jednotek/h na jednotlivých pozicích k optimalizaci celého procesu.
Modely simulace:
- Současná situace
- Optimalizace počtu operátorů závisející na denním příjmu jednotek (současný systém)
- Optimalizace počtu zpracovaných jednotek na jednotlivých pozicích z vlastních zkušeností
- Maximální možné vytížení na modelu č. 3 a kapacitě provozovny
Popis procesu:
- Příjem jednotek
- Nahrání jednotek do systému + základní rozřazení dle hlášené chyby (2 kategorie – fyzické x sw poškození/chyba)
- Nabití všech jednotek (test baterie)
- Restore – Tovární nastavení jednotky
- Základní verifikace – ověření hlášené chyby zákazníkem
- SW kontrola funkce display + mechanická kontrola dotyku operátorem
- SW kontrola Audio – reproduktory + mikrofon
- Kontrola základních funkcí telefonu
- Test wifi (2,4 GHz, 5 GHz), Bluetooth, GPS
- Kontrola funkčnosti telefonické komunikace
- Vizuální kontrola jemného fyzického poškození
- Otevření jednotky a kontrola, zda nebyla jednota zasažena tekutinou
- Ověření, zda jednotka nebyla poškozena při otevření (opakují se body 6-10)
- Finální kontrola (vizuální kontrola + tovární nastavení)
- Očištění jednotek
- Balení
- Odeslání
Schváleno Tomáš (talk) 19:47, 8 May 2019 (CET)
Optimalizace centrálního skladu
Název simulace: Optimalizace centrálního skladu
Autor: Martin Jirsa
Modelovací nástroj: Simprocess
Předmět simulace: Obchodní společnost nakupuje zboží od různých dodavatelů. Zboží je dovezeno do centrálního skladu, kde je přerozděleno a odvezeno do menších skladů, které pak zboží distribuují koncovým zákazníkům (obchodníkům). Centrální sklad funguje převážně pro přerozdělování jednotlivých objednávek a vlastní skladovací zásoby jsou minimální. V této simulaci se budu věnovat pouze procesu přerozdělování na lokální sklady. Každý z lokálních skladů posílá objednávku na dané produkty. Veškeré objednávky jsou dodávány do centrálního skladu. Kde jej pracovníci přerozdělují dle kódu lokálních skladů. Každý pracovník má nyní zavedenou normu na hodinu, kolik musí přerozdělit krabic se zbožím. Lokální sklady je nacházejí v Ostravě, Brně, Plzni, Českých Budějovicích a v Liberci
Entity:
- Krabice
- Paleta
Modely:
- Vymodelování stávajícího procesu přerozdělování zboží mezi jednotlivými sklady, dle dat ze skladu.
- Model optimalizace počtu pracovníků dle denního příjmu na centrální sklad.
- Maximální možné vytížení skladu dle skladovacích a personálních kapacit.
Popis procesu:
- Příjem zboží – do skladu přijedou nákladní vozy od dodavatelů
- Složení zboží
- Kontrola objednávky (zda dorazilo vše co bylo objednáno) a pokud ne - reklamace (řešeno procentuální chybovostí ze získaných dat)
- Načtení zboží do systému
- Třídění zboží pro lokální sklady
- Balení
- Odeslání
- Odkud budete mít podkladová data? Tomáš (talk) 12:39, 19 May 2019 (CET)
- Martinus (talk) 13:53, 19 May 2019 (CET) Data budou poskytnuta od kolegy, který v tomto skladu pracuje na pozici Shift leadera.
- Dejte si pozor na ta data. Není moc dobré, že je - chápu-li to dobře - nemáte nyní k dispozici. Bude nutné je odzdrojovat, tudíž uvést název té firmy, atd. (pozor, bylo by dobré, aby o tom daná firma věděla, ty práce jsou veřejné). Jinak schváleno.
- Martinus (talk) 13:53, 19 May 2019 (CET) Data budou poskytnuta od kolegy, který v tomto skladu pracuje na pozici Shift leadera.
Simulace výběru pokladny na prodejně
Název simulace: Simulace výběru pokladny na prodejně
Autor: Jan Hazdra
Typ modelu: Diskrétní simulace
Modelovací nástroj: SIMPROCESS
Definice problému: Pracuji v Makru, jde o společnost zaměřenou na velkoobchodní prodej nejen potravinářského spotřebního zboží. V centrálním obchodě používáme několik různých typů pokladních systému a druhů pokladen. Jsou zde pokladny klasické s obsluhou, samoobslužné a nově v pilotním provozu tzv. scan pokladny. Ve skutečnosti jde pouze o váhu, samotné markování artiklů probíhá přes mobilní aplikaci. Váha pak jen několika způsoby porovnává obsah košíku s obsahem virtuálního namarkovaného košíku v aplikaci a při shodě přechází k placení.
Metoda: Problém bude řešen jako diskrétní simulace v programu Simprocess, jelikož jde o variaci na problém front, který se v Simprocessu řeší nejsnadněji. Při simulaci vycházím z reálných dat posbíraných za jeden den na jedné z prodejen v České Republice. Data se během jednotlivých dnů příliš neliší, proto budu vycházet ze vzorku z jednoho dne.
Parametry:
- typ pokladny
- počet pokladen
- zdržení na pokladně
- počet zákazníků
- doba strávené na prodejně
Cíl simulace: Nasimulovat běžný provoz prodejny s třemi druhy pokladních systémů, výsledky by mohly vést k optimalizaci procesu placení na pokladnách (změnit počet a poměr pokladen, zobrazit vytížení a další).
Meziměstská autobusová doprava
Název: Simulace meziměstské autobusové dopravy
Autor: Zikl00 (talk) 12:25, 8 May 2019 (CET)
Nástroj: Vensim
Typ modelu: Systémově dynamický
Popis modelu: Jsme jedním ze zakladatelů dopravní společnost, která se zabývá meziměstskou autobusovou dopravou. Pomocí simulace budeme zjišťovat, v jakých městech se vyplácí provozovat autobusové linky společnosti. Konkurence se nebere v této úloze v úvahu. V simulaci půjde o ekonomické řízení podniku, kde se budou sledovat příjmy a výdaje. V úvahu se bere např. pořizovací cena autobusů a počty pasažérů. Dále musí společnost platit své řidiče a náklady na provoz autobusů. Aby přeprava byla výdělečná, bude záležet také na počtu autobusů. Ty mají danou kapacitu, opotřebení, fixní a variabilní náklady na provoz. Sledovat se bude výdělečnost a ztrátovost přeprav.
Parametry modelu:
- Počet cestujících na nádražích
- Velikost populace jednotlivých měst
- Vzdálenost mezi městy
- Počet autobusů
- Pořizovací cena jednoho autobusu
- Počet řidičů
- Náklady na provoz jednoho autobusu
- Náklady na jednoho řidiče
- Cena paliva
Cíl simulace: Výsledky simulace budou sloužit jako podpora při ekonomickém řízení společnosti. Zjistíme, za jakých podmínek se vyplatí provozovat služby společnosti. Můžeme tak i předejít negativním vlivům a budoucím ztrátám.
- Téma samotné se mi líbí, upřesněte prosím ale, kde vezmete data. Bude jich potřeba docela dost. Kupříkladu vytíženost autobusů během dne/týdnu, celkové náklady na vlastnictví/provoz autobusů (údržba, lidské zdroje, redundance, palivo, amortizace, pojištění, atd...). Pokud máte hodnověrné zdroje, na základě kterých jste schopen takové parametry nastavit, tak je to super zadání. Tomáš (talk) 20:20, 8 May 2019 (CET)
- Nakonec jsem se rozhodl pro malou úpravu zadání a změnu nástroje. Zikl00 (talk) 20:47, 13 May 2019 (CET)
- Schváleno Oleg.Svatos (talk) 15:15, 14 May 2019 (CET)
Retence vody v krajině
Název: Simulace retence vody v krajině
Autor: Jan Reindl
Nástroj: Netlogo
Popis simulace: Prostředí tvoří krajina s různě složitým terénem, na který dopadá různé množství srážek. Část vody se vsákne, ale zbytek teče směrem dolů. V místech, kde protéká hodně vody může docházet k erozi. Pokud voda odtéká příliš rychle, půda vysychá. Půda má dvě "vrstvy" první vrstva je povrchová, s omezenou možností absorbovat vodu. Druhá vrstva je hluboká a má relativně neomezenou kapacitu, voda se do ní ale dostává postupně skrze svrchní vrstvu. Uživatel bude mít možnost na jednotlivých "dlaždicích" možnost uměle zvýšit nebo snížit elevaci (vytvořit hráz nebo vykopat příkop). Model bude sledovat množství vsáknuté vody, hladinu "spodních vod", množství vody, která odteče pryč, a závislost těchto výsledků na vydatnosti a četnosti srážek. Jedná se o dnes často zkoumaný problém, a neměl by být problém sehnat data pro relativně přesné nastavení modelu.
Parametry modelu:
- Vydatnost srážek
- Četnost srážek
- Absorbční schopnost půdy
- Absorbční kapacita půdy
- Pevnost půdy (odolnost proti erozi)
- Množství vody v jednotlivých vrstvách půdy
- Rychlost úbytku vody v půdě
Možnosti rozšíření modelu:
- Různé druhy půdy (les, pole s řepkou,...)
- Možnost přidání lidského osídlení, které může ohrozit povodeň.
- Více možných terénních úprav
- Různé možnosti generace nebo vložení "mapy"
Xreij15 (talk) 09:58, 12 May 2019 (CET)
- Jsem pro, vezměte ale prosím nějaké zcela konkrétní území, které budete simulovat, optimálně takové, pro které jsou dostupná data. Schváleno. Tomáš (talk) 16:51, 12 May 2019 (CET)
Simulace populačního vývoje České republiky
Název simulace: Simulace populačního vývoje České republiky
Autor: Bc. Adam Spivák, spia00
Typ modelu: Systémově dynamický
Modelovací nástroj: Vensim
Popis Modelu: Model zobrazuje vývoj počtu obyvatel České republiky v závislosti na střední délce života, poměru počtu mužů a žen, průměrném věku rodiček, míře plodnosti, zásahu státu, živelných katastrofách (např. povodně), migrace. Model bude využívat dostupná statistická data týkající se České republiky.
Parametry modelu:
- Počáteční počet obyvatel
- Střední délka života
- Poměr mužů a žen
- Průměrný věk rodiček
- Míra plodnosti
Cíl simulace: Zobrazit v přehledné formě vývoj počtu populace v závislosti na zadaných parametrech.
- Pokud to bude obsahovat komplexně zpracované všechny proměnné uvedené v popisu modelu, tak schváleno.
Simulace parkoviště
Název: Využití smartphonů k optimalizaci parkování
Autor: Matyáš Svárovský
Typ modelu: Multiagentní
Modelovací nástroj: NetLogo
Popis modelu:
Model bude multiagentní simulací parkoviště. V jednom případě budu modelovat klasické chování řidičů aut, kdy po vjezdu na parkoviště hledají volné místo a zaparkují. Řidiči nevědí, kde se nachází volné místo, ale chtějí stát co nejblíže u východu a podle toho prohledávají parkovací prostor. Druhá varianta zahrnuje smartphone aplikaci, která sleduje aktuálně volná/plná místa a také místa, která budou obsazená. Nově příchozím řidičům poskytne informace o volném parkovacím místě a ti jedou bez hledání přímo do cíle.
Cíl modelu:
Porovnat dva modely - bez/s navigací. Sledovat u každého modelu dobu potřebnou pro nalezení parkovacího místa. Sledovat tento čas také podle velikosti parkoviště a aktuálního počtu aut.
Pozorovat zaplňování parkovacího prostoru v závislosti na době dne (viz parametry) a v závislosti na výjezdech a jejich umístění.
Parametry modelu:
- Počet parkovacích míst
- Počet vjezdů/výjezdů
- Průměrný počet aut na začátku dne, během peak hour, na konci dne (tohle bych měl raději jako parametry, ať mohu pozorovat rozdíl mezi prázdnějším a plným parkovištěm, než hledat konkrétní, pevná data)
- Tohle vypadá jako jedna z mnoha variant klasického modelu predator-prey. Ten byl zpracován už asi tisíckrát. Nemám problém zpracovat jej potísícíprvní, nicméně, musí tam být nějaká jasná přidaná hodnota. Možnost, která by asi šla realizovat, je nesimulovat jakousi virtuální malou/velkou rybu, ale nějaké zcela konkrétní druhy, na základě nějakých jasných parametrů a tvrdých dat. To pochopitelně nevyhnutelně vyžaduje poměrně hlubokou rešerši v pramenech z oblasti biologie. Tomáš (talk) 12:36, 19 May 2019 (CET)
- Mohu se tedy podívat po konkrétních datech a vytvořit druhy ryb (a případně dalších živočichů) odpovídající nějakému reálnému případu. Jednotlivé druhy pak budou mít různé vzorce chování, různé vlastnosti a podle potravního řetězce u daného případu vyřeším, kdo konzumuje koho. Jen se tedy bojím, abych při zvýšené realističnosti dostal vůbec nějaké hodnotné výsledky. Svam00 (talk) 17:59, 19 May 2019 (CET)
- Berte to tak, že tu úlohu byste měl být schopen vyřešit prakticky jen na základě tohoto zadání. Není tu jediné "tvrdé" číslo a ani ve zdrojích, které jste posktytnul, toho moc není. Kupříkladu, kolik dejme tomu joulů energie znamená růst gramu fytoplanktonu? A odkud jste to vzal? A to je ještě ten snazší problém. Co teprve ten vliv rybolovu? Máte tam hodně agentů, hodně proměnných, přičemž není jasné, jak ty hodnoty nastavíte. Já bych Vám fakt doporučoval, zkuste rychle nahodit něco jiného, tady byste si zavařil. Tomáš (talk) 00:46, 2 June 2019 (CET)